
karl. — Automated driving research platform used to deploy the Trustworthy AI perception component.

XAI Interface. — Embedded into the vehicle's dashboard for real-time inspection of the perception module.
Deep Neural Networks have become the dominant solution for Autonomous Driving perception, but their opacity conflicts with emerging Trustworthy AI guidelines and complicates safety assurance, debugging, and human oversight. While theoretical frameworks for safe and Explainable AI (XAI) exist, concrete implementations of Trustworthy AI for 3D scene understanding remain scarce.
We address this gap by proposing a Trustworthy AI perception module that is remarkably robust, integrates faithful explainability, and calibrated uncertainty estimates. Building on a transformer-based detector, we derive explanations from the attention mechanism at inference time and validate their faithfulness using perturbation-based consistency tests. We further integrate an uncertainty estimation and calibration module, and apply robustness-enhancing training methods.
Experiments show faithful saliency behavior, improved robustness, and well-calibrated uncertainty estimates. Finally, we deploy these Trustworthy AI elements in a prototype vehicle and provide an XAI Interface that visualizes documentation artifacts, model uncertainty state, and saliency maps, demonstrating the feasibility of trustworthy perception monitoring in real time.
Guided by the principles of Trustworthy AI, we focus on three measurable components: (i) Explainability for auditability and debugging, (ii) Uncertainty to quantify predictive reliability, and (iii) Robustness to maintain stable behavior under distribution shift. We instantiate these three components in a transformer-based LiDAR-camera detector and expose them through an XAI Interface that runs alongside the detector on a research vehicle.
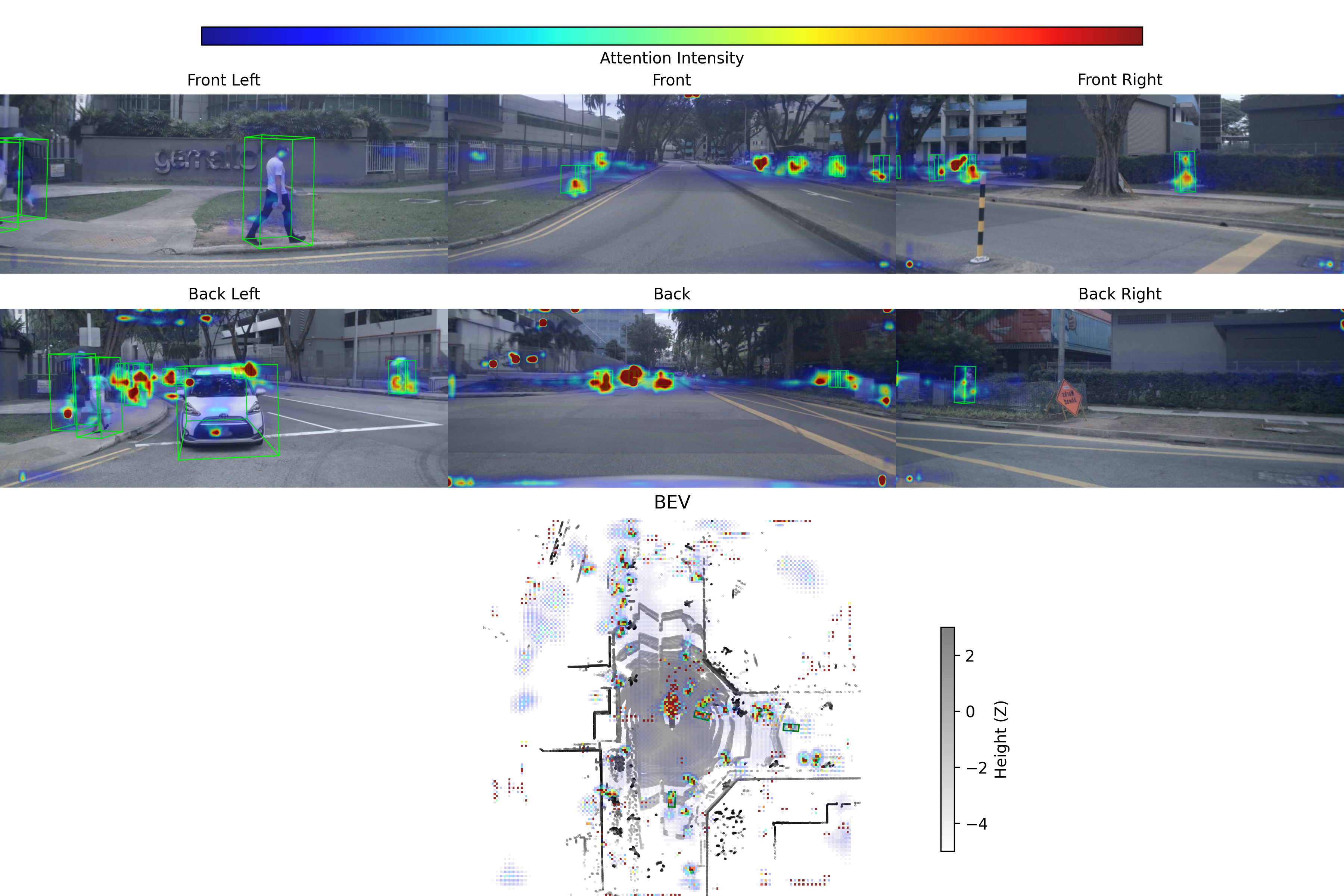
We build on CMT, a transformer-based multi-modal 3D object detection architecture. Multi-view camera images are encoded into image tokens, while the LiDAR point cloud is processed by a sparse encoder to produce point cloud tokens. A set of learnable object queries interacts with the concatenated 3D sensor tokens in a transformer decoder via cross-attention, producing refined queries that are decoded into 3D bounding boxes, class scores, and per-parameter uncertainty estimates. The cross-attention weights are extracted at inference time and serve as a faithful explanation of which sensor tokens contributed to each detection.
For each decoder layer \( \ell \in \{1, \dots, L\} \), we retrieve the cross-attention tensor \( A^{(\ell)} \in \mathbb{R}^{H \times Q \times S} \), where \(H\) is the number of heads, \(Q\) the number of object queries, and \(S\) the number of source tokens (LiDAR plus image tokens). We filter queries by top-\(K\) selection and a confidence threshold \( \tau \), then aggregate the remaining attention across layers and heads via mean-fusion, followed by max-pooling over queries to produce a single per-token importance score. The resulting saliency is split into modality-specific maps over the BEV LiDAR grid and the per-view image patch grids, yielding qualitative overlays and a basis for perturbation-based faithfulness tests. In addition, we compute a Sensor Contribution score \( C_m \), i.e., the fraction of total fused attention mass assigned to each modality \(m\), and visualize \( C_m \) alongside detections and saliency maps to summarize per-sensor reliance.

We extend the detector with an uncertainty head that outputs per-parameter variance estimates for each 3D bounding box. The box centroid \((x,y,z)\) is modeled with independent Gaussians via the KL-divergence objective, and yaw \( \theta \) is modeled with a von-Mises distribution to respect angular periodicity. For deployment-friendly calibration, we apply post-hoc Temperature and Platt scaling to classification logits, and fit per-parameter regression temperatures for \( \sigma_x, \sigma_y, \sigma_z, \kappa_\theta \) by minimizing the Miscalibration Area (MCA) on a held-out split. Calibration is evaluated via Detection-ECE for classification and MCA for regression, following our prior work Query2Uncertainty.
To improve robustness under modality degradation and distribution shift, we adopt a masked-modal training strategy: during training, entire sensor modalities are randomly masked so the detector is exposed to LiDAR-only, camera-only, and full LiDAR-camera inputs. This discourages over-reliance on any specific sensor while keeping the architecture unchanged. We assess robustness on MultiCorrupt, reporting the mean Relative Resistance Ability (mRRA) across corruption types and severities.
We deploy a prototype of the Trustworthy AI perception component on karl., an automated driving research platform, demonstrating the real-world integration of explainability, uncertainty quantification, and calibration in a live AD stack. For practical integration under limited training data, the prototype currently operates in a LiDAR-only configuration: we fuse two front-facing Ouster OS1-128 LiDARs as input to the transformer-based detector and accelerate the model with TensorRT and FP16 quantization, achieving \(24.4\,\mathrm{ms}\) average inference latency (99th-percentile: \(28.8\,\mathrm{ms}\)) on an NVIDIA RTX 4090. The detection pipeline is implemented as a ROS 2 Jazzy node, and the real-time XAI Interface is implemented as an RViz plugin that visualizes Model Cards and Data Cards, detections with uncertainty estimates, attention-based saliency maps, and per-sensor contribution scores.
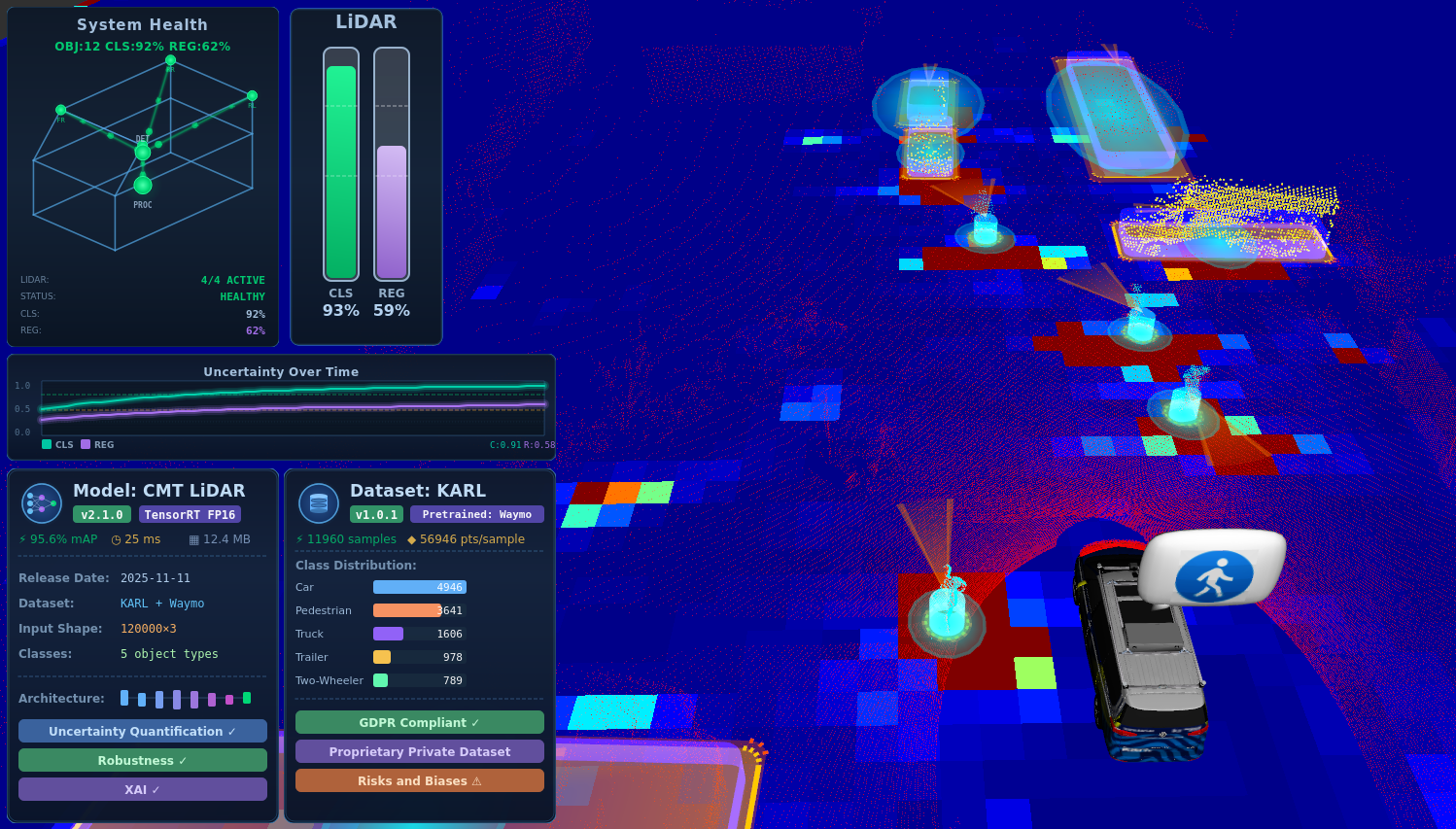
We provide a Model Card documenting the model architecture, training protocol, intended use, and known limitations, as well as a Data Card for the dataset used to fine-tune and calibrate the prototype, covering data collection, annotation, biases, and class distributions. Both documents are available above as PDF downloads and are surfaced directly inside the in-vehicle XAI Interface.
We evaluate explainability via perturbation-based faithfulness tests, uncertainty calibration via Detection-ECE and MCA, and robustness on the MultiCorrupt benchmark. Attention-derived saliency yields more faithful explanations than baseline methods, post-hoc calibration improves both classification and regression reliability without affecting accuracy, and masked-modal training improves stability under sensor degradations and adverse-weather corruptions.
@inproceedings{beemelmanns2026trustworthy,
title={Towards Trustworthy and Explainable AI for Perception Models: From Concept to Prototype Vehicle Deployment},
author={Beemelmanns, Till and Sharifi, Shayan and Mehrotra, Manas and Choudhuri, Ayushman and Eckstein, Lutz},
booktitle={IEEE International Conference on Intelligent Transportation Systems (ITSC)},
year={2026},
address={Naples, Italy},
}